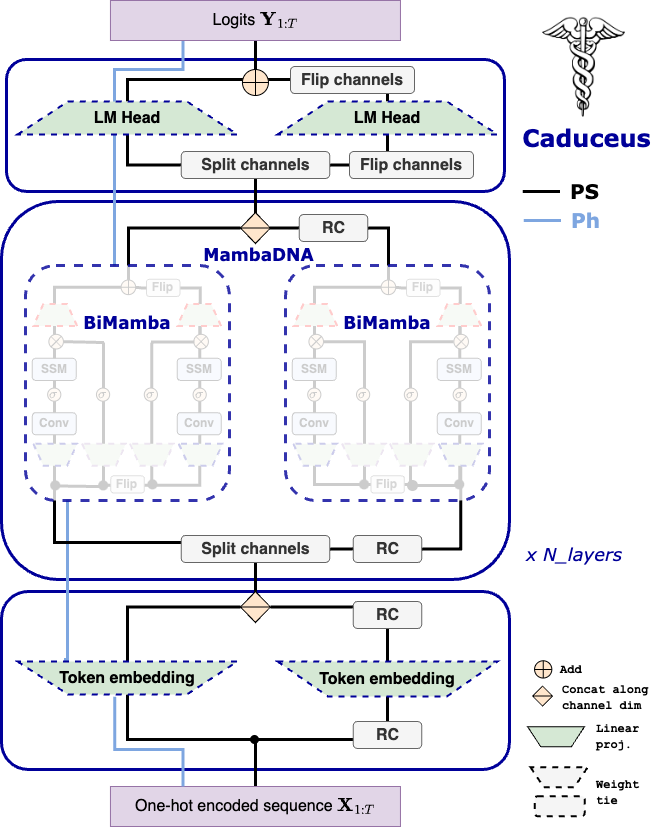
We pre-trained models on the human reference genome.
Similar to the preliminary results in
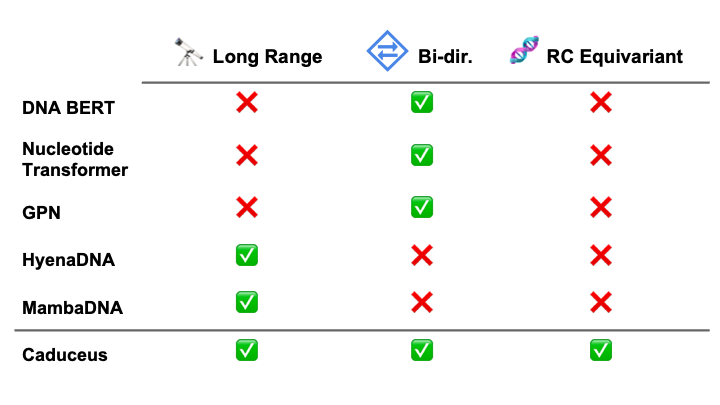
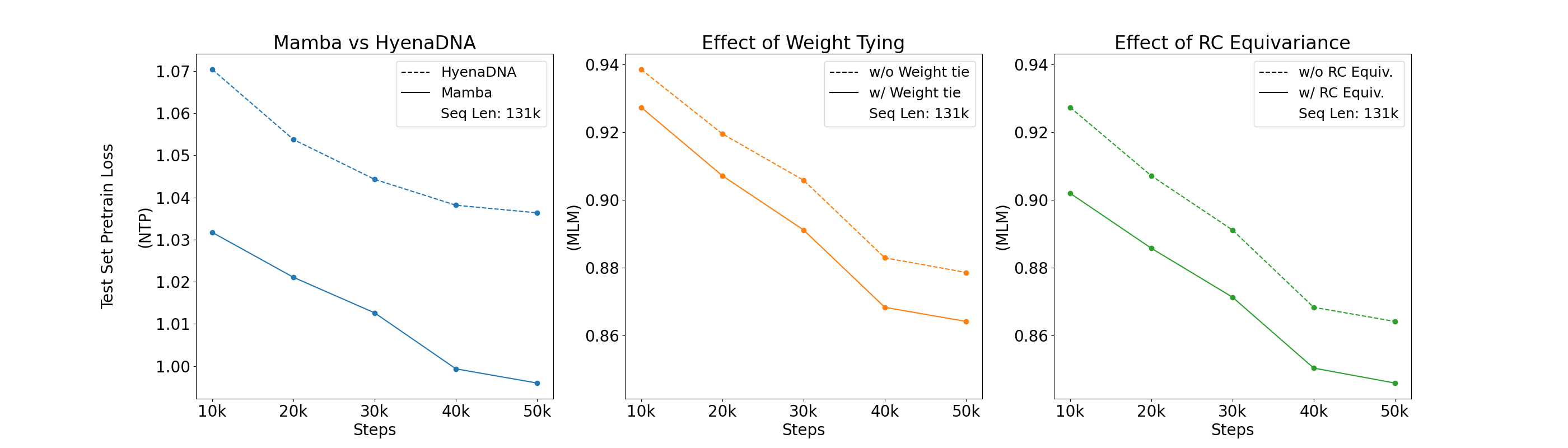
Gu et al. (2023), we find that the Mamba module performs better than Hyena (
Nguyen et al. (2023)) in terms of next token prediction (see figure below on the left).
This result lend support to our choice of Mamba as the inner building block of our models.
Additionally, we find that the efficient parameter usage of BiMamba, which allows us to train deeper models for comparable parameter counts relative to not using weight tying, leads to better pre-train performance (see the middle figure below).
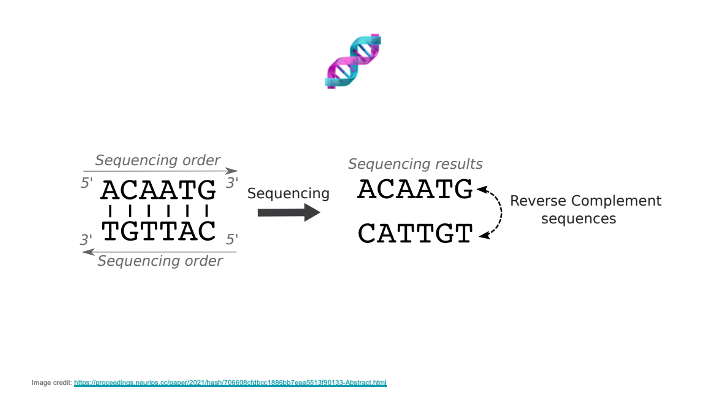
Finally, we find that RC equivariant LM leads to better masked language modeling pre-training loss (see figure below on the right).
These results are significant because performance on the MLM task has grounding in the biology of downstream tasks, such as variant effect prediction.
We evaluate models on a range of biologically relevant downstream tasks, as described below.
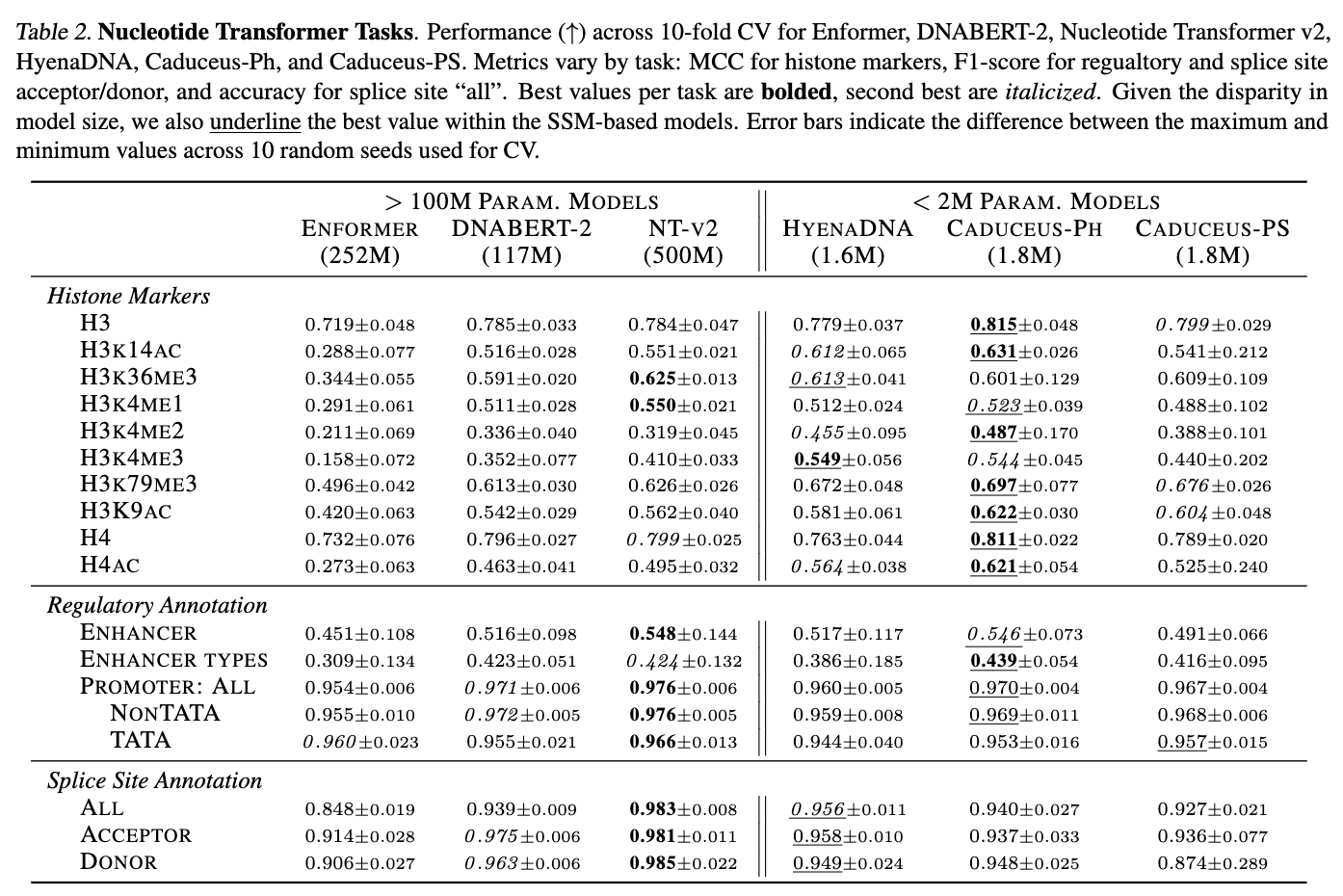
One set of benchmarks comes from the suite of tasks introduced in Nucleotide Transformer (Dalla-Torre et al. (2023)).
We find that Caduceus-Ph performs competitively, even beating attention-based methods with orders of magnitude more parameters on 8 of 18 prediction tasks.
Caduceus models outperform a similarly sized HyenaDNA (Nguyen et al. (2023)) model on almost all the histone marker and regulatory annotation tasks, while HyenaDNA performs better on splice site annotation.
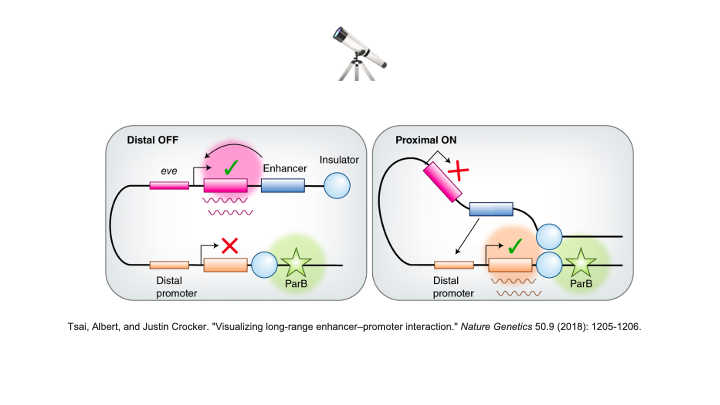
We explore the implications of long-range contexts on the task of predicting the effect of SNPs on gene expression.
There is biological evidence to suggest this task indeed entails long-range interactions.
Additionally it aligns well to LM pre-training objectives, which enable models to implicitly learn to recognize the effects of evolutionary pressure (e.g., conservation, co-evolution).
The dataset used in this task is derived from the Enformer paper (Avsec et al. (2021)) and presented in Trop et al. (2024).
From each model, we extract embeddings centered around the SNP location.
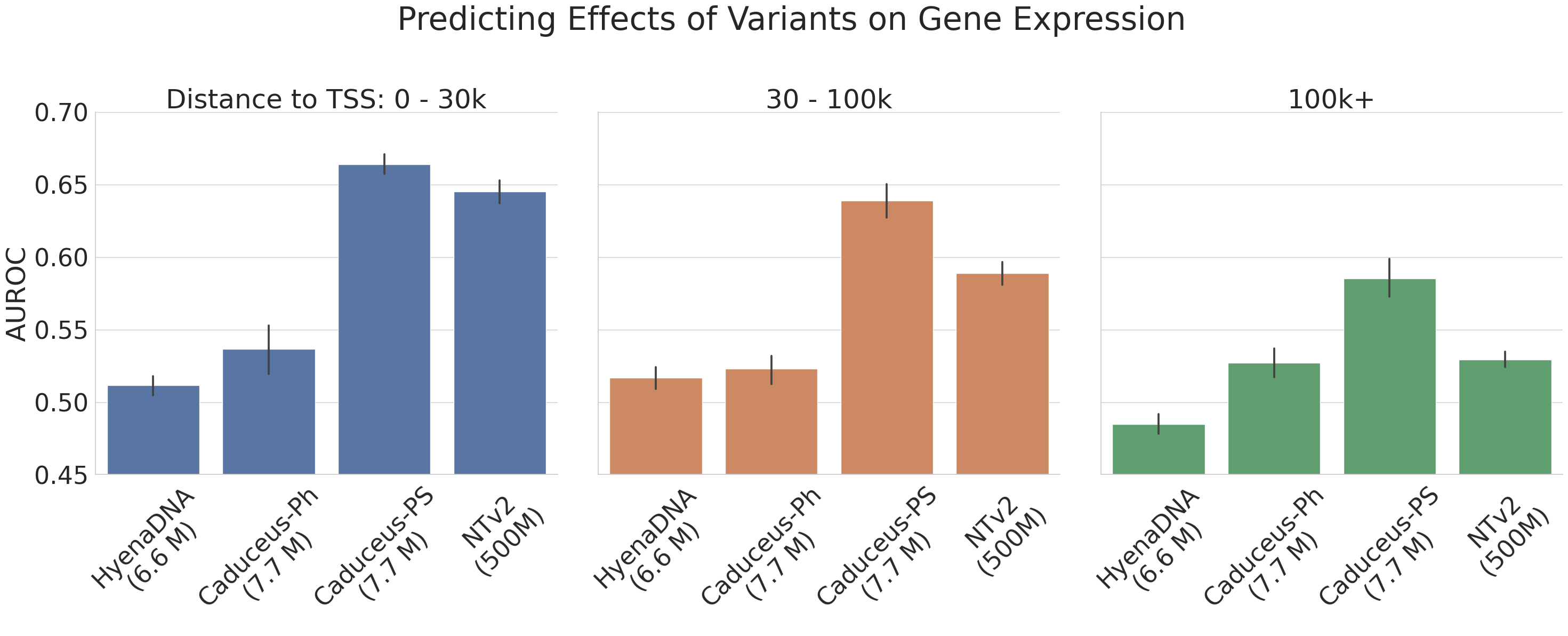
We stratify the data by distance of the SNP to nearest Transcription Start Site (TSS).
For each bucket, we sample 5,000 training points and fit an SVM classifier with an RBF kernel to predict VEP annotations.
We report test set AUCROC mean +/- standard deviation ranges for classifiers fit on 5 random training subsets.
We compare Caduceus to HyenaDNA, Nucleotide Transformer, and the suprevised baseline Enformer.
As shown in the figure below the Caduceus models consistently outperform HyenaDNA, and Caduceus-PS exceeds the performance of the Nucleotide Transformer v2 (with 500M parameters), especially as distance to the nearest TSS grows.
Of note, on sequences where distance to TSS exceeds 100k, Caduceus even outperforms the well-regarded Enformer baseline.
 Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
 2
Princeton
2
Princeton
 3
Carnegie Mellon
3
Carnegie Mellon